
Making your MongoDB queries work better is all about boosting speed and efficiency. But first, let’s check out the tool to spot those sluggish queries.
You can use the .explain() command, or if you prefer a visual look, open up MongoDB Compass, head to the ‘explain’ tab, and peek at the query stats.
Example :
db.collection.find().explain()
db.users.find({email:”randomjones@gmail.com”}).explain("executionStats")
Using the compass GUI :

After you do the explainStats thing, here’s what to watch for: If it says ‘COLLSCAN’ in the results, it means the whole collection got searched. But if it’s ‘IXSCAN,’ only the index keys were used. Remember, scanning the whole collection is a slowpoke move that can really mess up your query speed.
Now let’s see some ways of optimizing the MongoDB
1) Apply Indexes:
This can be achieved by either MongoDB compass or via the shell but first, let’s answer the question,
What are indexes?
Well, imagine you have a giant bookshelf with many books, and you want to find a specific book quickly. Indexes in MongoDB are like a set of bookmarks for your books.
An ascending index sorts the bookmarks in order, like A to Z. So, if you’re looking for a book in alphabetical order, it’s super-fast.
A descending index is like sorting the bookmarks from Z to A. This is useful if you often search for the latest stuff, like the most recent books.
With these bookmarks (indexes), MongoDB can jump right to the relevant data without reading every book (document). So, it makes finding information much faster and efficient.
To know more indexes follow this link : MongoDB Indexes
2) Apply Search Indexes:
In MongoDB, “indexes” and “search indexes” are often used interchangeably because both are about helping you find data faster. However, there can be a subtle difference in the context.
Search Indexes (or Text Indexes) are like super-smart indexes. They understand the words in a more natural way, almost like how a human would. They’re great for searching unstructured text data, like articles, blog posts, or comments, because they can find related words, not just exact matches.
To know about how to apply these, visit this link: Learn how to apply Search Indexes in MongoDB
3) Query Projection:
Retrieve only the fields you need by specifying the desired fields in the query using projection. This reduces data transfer and processing time.
4) Avoid Sorting:
If possible, avoid sorting large result sets, as it can be resource-intensive. Use indexes to cover sorting whenever feasible.
5) Connection Pooling:
Connection pooling is like having a bunch of reusable pipes for water. When you need water (database connections), you don’t have to build a new pipe every time. Instead, you grab an available one from the pool.
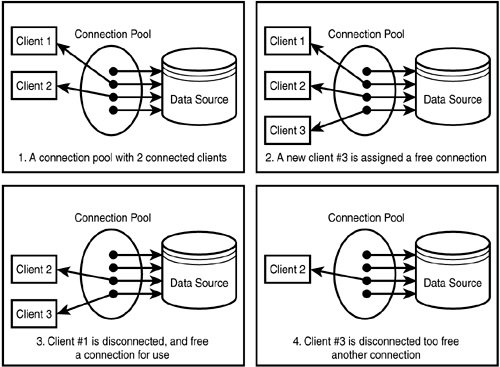
Referring to the above image, in part 2, a free connection (reusable pipe) was assigned to client 3 (water).
In part4 you can see 3 pipes ready to be reused for water. This exemplifies the efficiency of connection pooling.
So, with connection pooling, your database connections are ready and waiting, like pre-made pipes, making it faster and more efficient to get the data you need from the database. Most MongoDB software does this automatically to save time and resources.
6) Use Aggregation Framework:
In general, the aggregation framework is designed for efficient data processing and can be very fast for many use cases. It allows you to perform a wide range of data transformations, calculations, and filtering operations within the database, which can be more efficient than fetching and processing data on the client side.
7) Consider Sharding:
For very large datasets, Sharding can distribute data across multiple servers, improving read and write scalability. Sharding is a MongoDB feature designed to address the challenges of scaling horizontally, which means distributing data across multiple servers or nodes.
Sharding divides your data into smaller, more manageable chunks called “shards.” Each shard is stored on a separate server or replica set. This distribution ensures that no single server becomes a bottleneck, and the load is evenly spread across multiple machines.
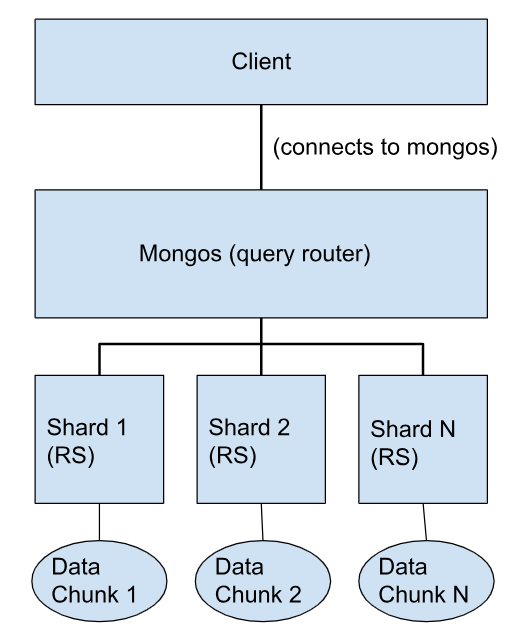
- The client connects to the mongos process.
- Mongos receives the client’s request and determines which shard(s) hold the relevant data based on the sharding key.
- Mongos routes the request to the specific shard(s).
- Each shard processes the request independently on its local data chunk.
- Mongos aggregates the results from all relevant shards and returns a unified response to the client.
8) Cache Your Data-heavy-APIs:
Caching your API refers to the practice of storing the responses generated by your application’s API in a temporary storage location, known as a cache, so that subsequent requests for the same data or resource can be served faster.
You can also cache API responses with Redis in a MongoDB and NodeJS stack.
Conclusion:
In conclusion, optimizing MongoDB involves utilization of indexes, including search indexes for efficient data retrieval. Query projection, avoiding unnecessary sorting, and implementing connection pooling enhance performance. Use of the aggregation framework for in-database data processing and considering sharding for large datasets contribute to scalability. Additionally, caching data-heavy APIs, possibly with Redis in a MongoDB and NodeJS stack, further accelerates response times. Employing these optimization techniques ensures enhanced speed, efficiency, and overall performance in MongoDB queries.

